Horizontale en verticale architectuur
Een typische applicatie bestaat uit (ten minste) drie lagen: eentje voor de user interface (UI), de businesslogica (ook wel het domein genoemd) en de datatoegang. Dat is één van de dingen die mij al vroeg werd geleerd toen ik begon met software ontwikkelen.
Je kunt dit model visualiseren als drie blokken die boven op elkaar liggen: de UI bovenop, de businesslogica in het midden en de datatoegang onderop. - De volgende afbeelding pluk ik schaamteloos van Wikipedia:
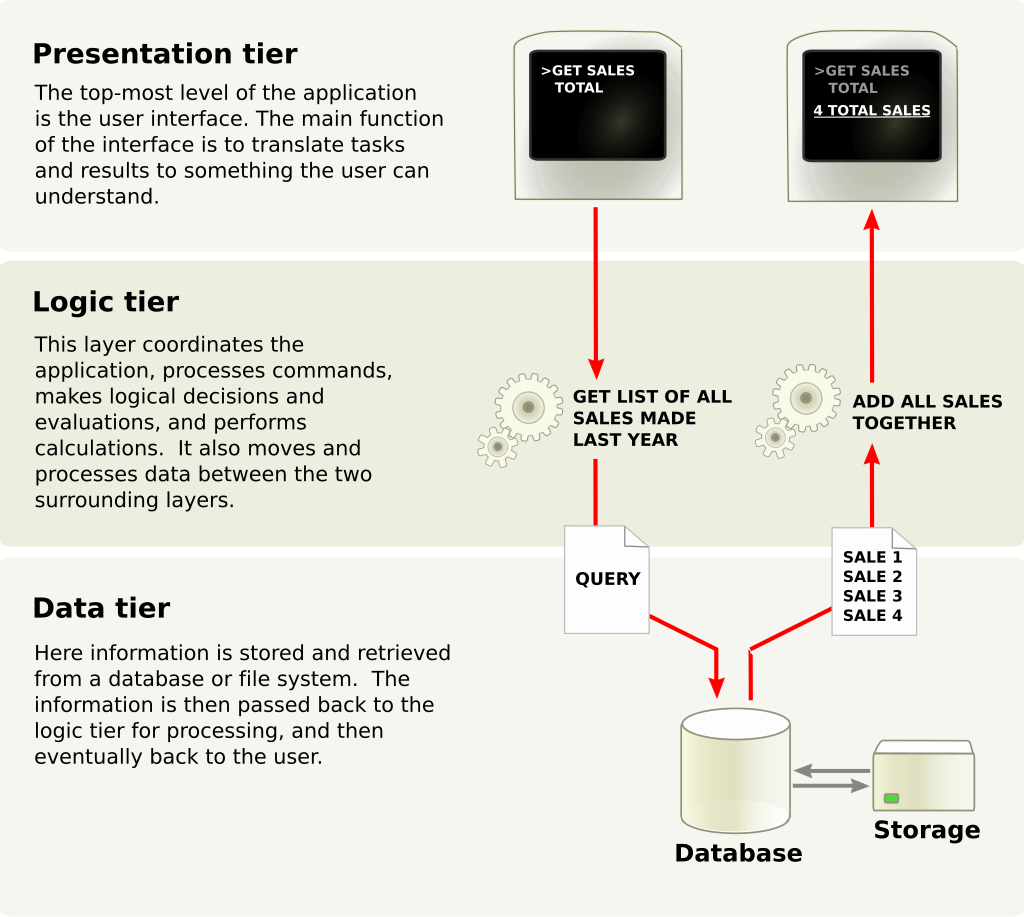
Een typische solution in de .NET-wereld bestaat dan ook uit drie projecten, die corresponderen met elke laag.
Afhankelijkheden
Het UI-project heeft een afhankelijkheid naar de businesslogica, en de businesslogica naar de datatoegang. Anders gezegd: elke laag, elk project is afhankelijk van de directe benedenbuur - en nooit andersom. Dat is een typische manier om je afhankelijkheden vast te leggen.
Een alternatieve manier van afhankelijkheden vastleggen is de volgende: de UI en de datatoegang zijn afhankelijk van de businesslogica.1 Ook hier is er sprake van een lagenmodel, maar deze wordt iets anders gevisualiseerd. Je kunt deze opzet het best zien als een ui met de businesslogica in het midden en de UI en datatoegang aan de buitenzijde.
Opnieuw komt Wikipedia to the rescue:

Horizontaal
Hoe je de afhankelijkheden ook legt, beide modellen gaan uit van een aantal lagen - die gedefinieerd worden door hun technische verantwoordelijkheden. In de literatuur wordt dit ook wel een horizontale verdeling van verantwoordelijkheden genoemd. (- Wat een verticale verdeling is? Daar kom ik zo op.)
Ook de applicatie die mijn team en ik op dit moment onderhouden - hoewel op diverse plekken al uitgebreid met bijvoorbeeld Azure Functions - kent ruwweg de hierboven beschreven opzet.
De laatste tijd ben ik na aan het denken over de implicaties van deze opzet.
Naamgeving
De directe aanleiding is een ongemak dat ik ervaar in de naamgeving van onze domeinobjecten.
De applicatie van mijn team houdt zich bezig met item- en toetsconstructie. Je zou items, heel kort door de bocht, kunnen kenschetsen als toetsvragen, en toetsen als verzamelingen items die als doel hebben een bepaald kennisniveau of vaardigheid te meten.
Het hoeft niemand te verbazen dat onze applicatie een object genaamd Item kent - het zou vreemd zijn als dat niet zo is. De vanzelfsprekendheid van Items in onze applicatie, is een erfenis van Eric Evans’ Domain-Driven Design (DDD).
Eén van de dingen die Evans stelt in zijn klassieke Domain-Driven Design: Tackling Complexity in the Heart of Software, is dat de code van een applicatie de taal van de eindgebruiker moet spiegelen. Spreekt een gebruiker over een item, dan moet de code daar ook over spreken.
Het is uit den boze dat ontwikkelaars zelf termen gaan verzinnen om domeinobjecten mee te representeren. Die praktijk werkt alleen maar spraakverwarring in de hand.
Varianten
Maar ons model kent naast Item ook een AssessmentTestItem2 - dat is een item zoals deze in de toets bestaat. En het kent ook een ItemBankItem2 - dat is een item zoals deze verschijnt in een itembank verschijnt. (Een itembank is, simpel gezegd, een verzamelingbak waar je items uit kunt plukken om in een toets te stoppen.)
Die objecten bestaan natuurlijk niet voor niets. Een item in isolatie (Item) is iets heel anders dan een item zoals vastgelegd in een toetsobject (AssessmentTestItem). Binnen de context van een toets is bijvoorbeeld de iteminhoud niet bijster interessant. Vanuit het perspectief van de toets is het alleen belangrijk om wat metadata van het item te kennen - de titel, bijvoorbeeld, en het id.
Je zou het zo kunnen zien: een toets is een verzameling verwijzingen naar items. AssessmentTestItems zijn in essentie verwijzende objecten, en ze verwijzen naar Items. Hetzelfde geldt, in een iets andere context, voor ItemBankItems.
Probleem
Maar: er is geen enkele eindgebruiker die deze termen bezigt. Eindgebruikers spreken van “items” - punt. Onze applicatie schendt daarmee één van de kernprincipes van DDD.
Daarmee maken wij als softwareontwikkelaars ons werk moeilijker dan nodig. Elke keer als een gebruiker het ontwikkelteam vraagt om deze of gene feature voor een item te implementeren, dan moeten wij ons afvragen: bedoelt ‘ie een Item, een AssessmentTestItem of een ItemBankItem?
En het ergste is: we kunnen de eindgebruiker niet eens vragen welke van de drie het is, want hij kent twee van de drie termen geeneens. Zijn antwoord zal waarschijnlijk bestaan uit een raadselachtige blik, gevolgd door: “Gewoon, een item.” - En daar heeft ‘ie gelijk in ook.
Domeinen
Hoe heeft deze situatie kunnen ontstaan? Wat is de oorzaak van dit ongemak?
Ook hier valt er iets te leren van DDD. Wanneer door eindgebruikers dezelfde term wordt gebezigd voor ogenschijnlijk verschillende concepten, dan is er waarschijnlijk sprake van verschillende domeinen.
Dat dit hier het geval is, moge duidelijk zijn. “Item” kan zowel item in isolatie, item in een toets en item in een itembank betekenen. Elke betekenis hoort bij een welonderscheiden domein: het domein itemconstructie, toetsconstructie en itembankbeheer.
Wat van buitenaf een dubbelzinnigheid leek, blijkt eenduidig zodra het in de juiste context wordt geplaatst.
Verticaal
Wat heeft dit te maken met de horizontale verdeling die ik hierboven noemde? Nou, het is natuurlijk geen vanzelfsprekendheid dat je je applicatie op een horizontale manier opzet. Je zou de verantwoordelijkheden ook op een verticale manier kunnen opzetten.
Wanneer je verticaal naar een applicatie kijkt, dan deel je de boel op in features. Je scheidt een applicatie niet op technische verantwoordelijkheden, maar op domeininhoudelijke.
Misschien raad je al waar ik naartoe wil. Verticaal bekeken, bestaat onze applicatie uit (ten minste) drie clusters van features: itemconstructie, toetsconstructie en itembankbeheer - de drie domeinen die ik hierboven noemde.
Als we onze applicatie verticaal op zouden hakken, dan zouden we af kunnen komen van onze ongemakkelijke naamgevingsconventies. Elk deelgebied zou zijn eigen project krijgen, en elk project zijn eigen model. Of het nu over items in isolatie gaat, of items in een toets, of items in een itembank - we zouden in de code altijd over Item kunnen spreken - net als de gebruiker.
Het kernprincipe van DDD wordt daarmee gerespecteerd. De Toren van Babel is afgebroken: ons monolitisch model is opgehakt in verticale opgezette minimodelletjes die elk één domein representeren - en niet meer.
Niets nieuws
De ideeën die ik hier presenteer zijn niet nieuw, natuurlijk - zelfs niet voor mij. Robert C. Martin raadde in Clean Architecture - nota bene: het op één na beste boek dat ik in 2020 las! - al een verticale architectuur aan.
En Jimmy Bogard spreekt al jaren over Vertical Slice Architecture. Een tijd terug heb ik nog een praatje van een heel uur erover lopen kijken:
Toch duurde het nog een goed half jaar voordat het kwartje eindelijk viel! Want hoewel ik al eerder van die concepten kennis had genomen, had ik ze altijd - min of meer onbewust - weggewuifd onder het mom van: maar dat is niet hoe een typische architectuur eruit hoort te zien. Die hoort er immers uit te zien zoals op de afbeeldingen hierboven!
Ook toen ik me meer ging verdiepen in softwarearchitectuur - Fundamentals of Software Architecture is een aanrader! -, lag de focus altijd op de technische verantwoordelijkheden van elk deel van de architectuur. Dat elke applicatie een opzet - zelfs op het hoogste architecturele niveau - zou kunnen hebben die het probleemdomein spiegelt, kwam eenvoudigweg niet in me op.
Er waren heel wat ongemakkelijke soorten Item-varianten voor nodig voordat dat kwartje viel. Maar de uitdaging die dat besef presenteert is nog veel groter: moeten wij onze horizontale applicatie nu om gaan bouwen naar een verticale variant - en hoe pakken we dat dan in hemelsnaam aan?
Dit model is onder verschillende namen bekend. Robert C. Martin noemt het “clean architecture”. “Hexagonal architecture”, ook wel “ports and adapters” genoemd, en “onion architecture” zijn ook twee veel voorkomende termen. ↩︎
Ik heb de naamgeving wat versimpeld voor deze blog - ontwikkelaars zijn immers heel goed in het pre- en postfixen van namen met allerlei technische implemenatiedetails. Maar die details zijn gelukkig niet nodig om mijn redenering te begrijpen. ↩︎ ↩︎
domain-driven design · domeinmodel · leermoment · naamgeving · software architectuur